Трейси LangGraph у Arize Phoenix¶

У Expert Memory Machine у langgraph.json зараз 15 LangGraph-графів:
bookmark-classifierbookmark-scrapercontent-classifierconfluence-agentfile-system-agentjd-classifiernotifications-agentfinance-trackervector-store-agenttask-managercalendar-agentinvoice-agentinvoice-schedulersdlc-agentprocess-manager
Коли щось «зависло» або відповідь дивна, логів зазвичай замало: видно рядок помилки, але не видно, який вузол графа скільки чекав і що саме пішло в модель.
Ось що я зробив: підключив Arize Phoenix як збірник трейсів поверх OpenTelemetry. OpenInference для LangChain підхоплює LangGraph (ainvoke, invoke, astream_events) без правок у кожному агенті. Окремо ввімкнено AnthropicInstrumentor: у process-manager звіт з кнопки PM report викликає anthropic.messages.create напряму, без LangChain. Одного лише LangChain-патчу для такого виклику недостатньо, щоб у Phoenix з’явився LLM-span.
Ось як це працює¶
- Увімкнув змінну
PHOENIX_ENABLED=true. - Вказав, куди слати трейси:
PHOENIX_COLLECTOR_ENDPOINT(типовоhttp://localhost:6006/v1/traces) іPHOENIX_PROJECT_NAMEдля групування в UI. - На старті бекенду до завантаження графів викликається
init_phoenix_tracing(),phoenix.otel.register, потімLangChainInstrumentorіAnthropicInstrumentorна той самийtracer_provider. - Будь-який
graph.ainvoke(),graph.astream_events()з FastAPI абоgraph.invoke()з CLI потрапляє в трейс LangGraph-шляхом, якщо Phoenix доступний. Генерація інвойсів у бекенді теж іде черезgraph.invoke("invoice-agent")(два прогони: invoice + results), а не через прямі ноди, щоб той самий шлях потрапляв у трейси.
Нижче дві схеми: як одна ініціалізація покриває всіх агентів у процесі, і як у трейсі вкладаються вузли графа та виклики LLM.
Усі агенти → один TracerProvider → Phoenix¶
Інструментація вмикається один раз на процес. Патч OpenInference сидить у пам’яті поруч з LangChain/LangGraph: неважливо, який саме graph викликали, task-manager, calendar чи classifier, кожен invoke / astream проходить через ті самі хуки й віддає span-и в той самий експортер.
flowchart TB
subgraph boot ["Один раз при старті процесу"]
init["init_phoenix_tracing()"]
reg["register() → OTLP у PHOENIX_COLLECTOR_ENDPOINT"]
lc["LangChainInstrumentor()"]
ant["AnthropicInstrumentor()"]
init --> reg --> lc --> ant
end
subgraph pool ["Усі LangGraph-агенти в цьому процесі"]
g1["15 graphs з langgraph.json"]
end
subgraph per_run ["Кожен запит, будь-який graph"]
inv["ainvoke / astream_events / invoke"]
nodes["spans: вузли графа"]
llm["spans: LLM через LangChain"]
inv --> nodes --> llm
end
subgraph direct_sdk ["Прямий Anthropic SDK напр. PM report"]
amsg["messages.create"]
end
lc -.->|"патч"| pool
pool --> inv
llm --> exp["span-и → OTLP → Phoenix"]
ant -.->|"патч"| amsg
amsg --> exp
reg -.-> expregister задає спільний TracerProvider. Для агентів на LangChain дочірні LLM-span-и часто вкладаються під вузол графа; для anthropic.messages.create span-и з’являються завдяки AnthropicInstrumentor; чи буде ідеальне батьківське вкладення в один trace з weekly_report, залежить від контексту OTEL у конкретній версії, але виклик моделі в UI вже видно.
Один прогін: граф, вузли, LLM¶
Типова картина в UI: один trace на прогін, всередині вкладені span-и по ланцюгу LangGraph і окремі span-и на виклики моделі (як їх бачить openinference, залежить від версій, але ідея саме така).
sequenceDiagram
autonumber
participant App as FastAPI або CLI
participant Graph as LangGraph
participant Model as LLM клієнт
participant OTEL as OTEL SDK
participant PX as Phoenix
App->>Graph: ainvoke / astream_events
Note over Graph,OTEL: root / chain span
loop по вузлах графа
Graph->>OTEL: span вузла
alt вузол викликає модель
Graph->>Model: chat / completion
Model->>OTEL: дочірній span LLM
end
alt вузол викликає tool
Graph->>OTEL: span tool
end
end
OTEL-->>PX: OTLP tracesPhoenix UI¶
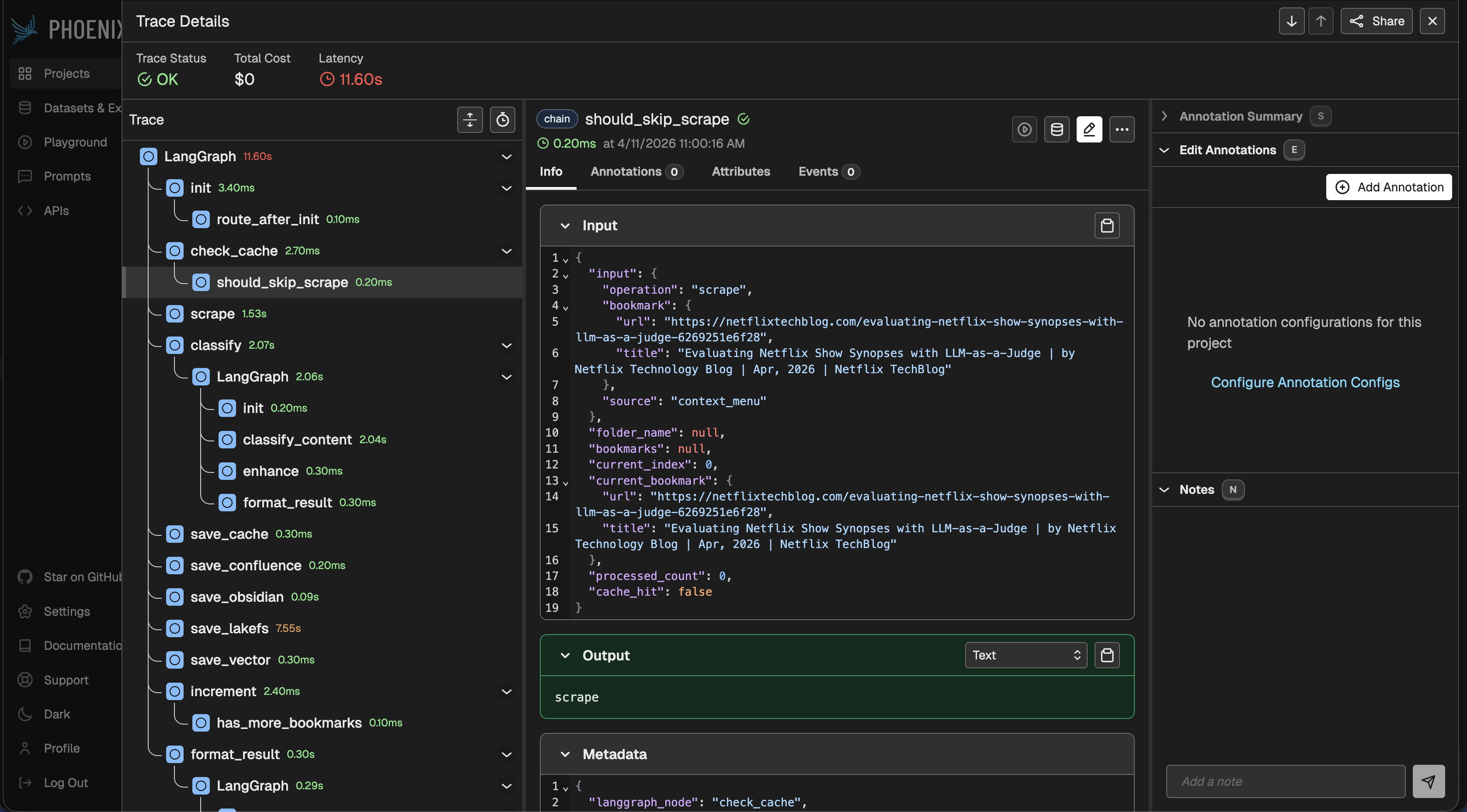
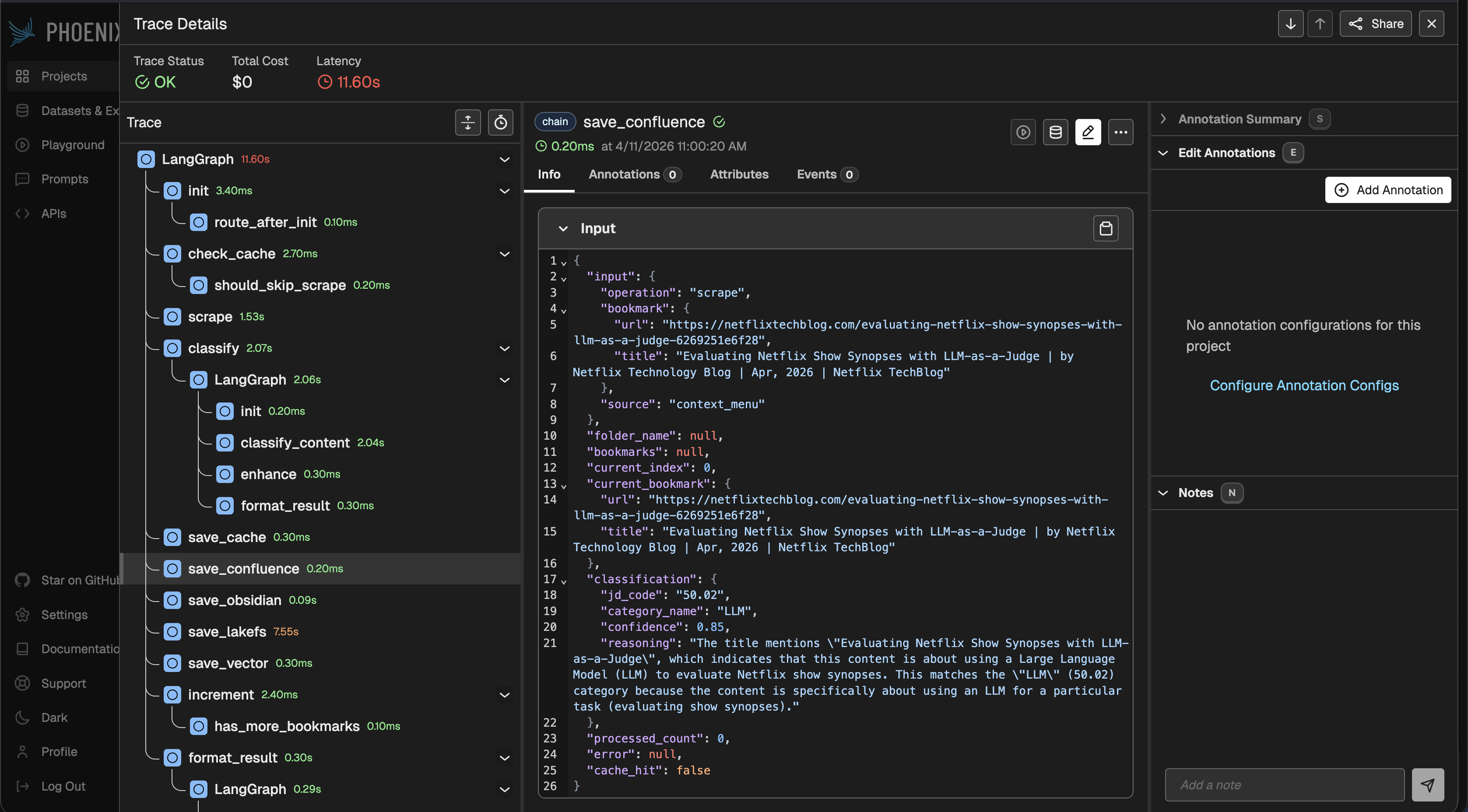
Код ініціалізації в core/observability/phoenix_tracing.py. Крім init_phoenix_tracing() для автоінструментації, модуль також експортує get_tracer(name) і trace_span(tracer, name, attributes), легкі хелпери для ручних span-ів у коді, що не проходить через LangChain (voice tools, avatar сесії, прямі HTTP-виклики чату):
def get_tracer(name: str) -> Tracer | None:
"""Повертає OTel tracer, або None якщо Phoenix не ініціалізовано."""
if not _initialized:
return None
from opentelemetry import trace
return trace.get_tracer(name)
@contextmanager
def trace_span(tracer, name, attributes=None):
"""Відкриває span якщо tracer не None; інакше no-op."""
if tracer is None:
yield None
return
with tracer.start_as_current_span(name, attributes=attributes or {}) as span:
yield span
Коли PHOENIX_ENABLED=false, get_tracer повертає None, trace_span віддає None без торкання OTel, нуль накладних витрат. Коли Phoenix увімкнено, span-и йдуть у той самий колектор, що й автоінструментовані.
Якщо немає LangChain-пакета або register / LangChainInstrumentor падають, повертається False. Блок Anthropic опційний: якщо пакета немає, у лог піде warning, але бекенд стартує (графові трейси лишаються, якщо LangChain ок).
Точки входу я зачепив у двох місцях:
- FastAPI: на початку
lifespan, щоб жоден graph не завантажився раніше за інструментацію:
@asynccontextmanager
async def lifespan(app: FastAPI):
from core.observability.phoenix_tracing import init_phoenix_tracing
init_phoenix_tracing()
# … решта старту
- CLI
deploy/langgraph/run_agent.py, той самий виклик перед завантаженням конфіга й графа.
Залежності в requirements.txt: arize-phoenix[evals], arize-phoenix-otel, openinference-instrumentation-langchain, openinference-instrumentation-anthropic.
Конкретний сценарій¶
Локально: підняв Phoenix (python -m phoenix.server serve або контейнер з образу arizephoenix/phoenix), у .env виставив PHOENIX_ENABLED=true, pip install з оновленого requirements.txt, перезапустив uvicorn на :8000. Перевірка: PM report на дошці задач (/api/process-manager/invoke), у Phoenix мають бути і вузли process-manager, і span на Anthropic. Окремо кнопка Generate weekly report у Team (/api/team/generate-weekly-report) як і раніше без LLM, лише шаблон і картки; трейс моделі там не очікується.
У проді або на спільному сервері зручніше вказати PHOENIX_COLLECTOR_ENDPOINT на один спільний інстанс, а не піднімати Phoenix у кожному docker-compose, інакше роз’їдуться версії й дашборди. Але тут є проблема: треба мережа й секрети до колектора; якщо endpoint недоступний, поведінка залежить від того, як OTEL експортер обробляє збої, не варто вважати, що «тихо проковтне» у всіх режимах.
За межами LangGraph: voice, avatar, chat¶
Автоінструментація покриває все, що проходить через LangChain. Але в EMM є три компоненти, які обходять LangChain повністю:
- Voice: Gemini Live працює на фронтенді через WebRTC; бекенд лише виконує tool calls (calendar, tasks, KB, web search) і створює токени.
- Avatar: Runway.ml real-time lip-sync сесії: створення, polling до READY, отримання WebRTC credentials.
- Izabella text chat: прямий HTTP до OpenAI, Ollama або Google; плюс MCP tool loop з кількома раундами function calling.
Жоден із них не продукує span-ів від LangChainInstrumentor чи AnthropicInstrumentor. Anthropic SDK виклики в Izabella chat трейсяться автоматично, але для OpenAI, Ollama й Google у коді лишаються звичайні httpx.post, без span-ів.
Рішення: ручні span-и через get_tracer / trace_span з того самого модуля. Кожен компонент отримує іменований tracer (emm.voice.tools, emm.avatar, emm.izabella.chat.llm, emm.izabella.chat.mcp) і обгортає ключові операції в span-и з корисними атрибутами.
Що тепер інструментовано¶
| Компонент | Назва span | Ключові атрибути |
|---|---|---|
| Voice токен | voice.token.create |
voice.token_type, voice.model |
| Voice tool call | voice.tool.invoke |
voice.tool.name, voice.tool.mcp_alias |
| Avatar сесія | avatar.session.create |
avatar.type, avatar.preset, avatar.session_id, avatar.poll_count |
| Chat LLM (Ollama) | chat.llm.ollama |
llm.provider, llm.model |
| Chat LLM (OpenAI) | chat.llm.openai |
llm.provider, llm.model |
| Chat LLM (Google) | chat.llm.google |
llm.provider, llm.model |
| Chat MCP loop | chat.mcp_loop.* |
llm.provider, llm.model, chat.mcp_rounds_total |
| Chat MCP tool | chat.mcp.tool |
mcp.alias, mcp.tool_name |
Приклад: коли користувач надсилає повідомлення в Izabella chat з LLM_PROVIDER=openai і активними MCP tools, у Phoenix видно батьківський chat.mcp_loop.openai span, всередині є дочірні chat.llm.openai (по одному на раунд) і chat.mcp.tool за кожен виклик функції, вкладені так само, як вузли LangGraph вкладаються під chain span.
Типовий трейс: Izabella chat з MCP tools¶
sequenceDiagram
autonumber
participant UI as Frontend
participant API as FastAPI
participant LLM as OpenAI / Ollama / Google
participant MCP as MCP tool server
participant OTEL as OTEL SDK
participant PX as Phoenix
UI->>API: POST /izabella-chat/sessions/{id}/messages
Note over API,OTEL: chat.mcp_loop.openai span
loop раунди з tools
API->>LLM: chat completion
Note over LLM,OTEL: chat.llm.openai span
LLM-->>API: tool_calls
loop по кожному tool call
API->>MCP: виклик tool
Note over MCP,OTEL: chat.mcp.tool span
MCP-->>API: результат
end
end
API->>LLM: фінальне completion
LLM-->>API: текстова відповідь
OTEL-->>PX: OTLP tracesТиповий трейс: voice tool invocation¶
sequenceDiagram
autonumber
participant FE as Frontend (Gemini Live)
participant API as FastAPI
participant Store as calendar / task / KB store
participant OTEL as OTEL SDK
participant PX as Phoenix
FE->>API: POST /voice/tools/invoke {name, arguments}
Note over API,OTEL: voice.tool.invoke span
API->>Store: handler(arguments)
Store-->>API: результат
API-->>FE: {result}
OTEL-->>PX: OTLP tracesПідсумок покриття¶
| Компонент | LLM трейси | Tool / API трейси |
|---|---|---|
| 15 LangGraph-агентів | Авто (LangChainInstrumentor) | Авто (LangChainInstrumentor) |
| Прямий Anthropic SDK | Авто (AnthropicInstrumentor) | -- |
| Voice (Gemini Live) | N/A (фронтенд) | Ручні span-и |
| Avatar (Runway.ml) | N/A | Ручні span-и (lifecycle сесії) |
| Chat (Anthropic) | Авто + loop span | Ручні span-и (MCP tools) |
| Chat (OpenAI) | Ручні span-и | Ручні span-и (MCP tools) |
| Chat (Ollama) | Ручні span-и | Ручні span-и (MCP tools) |
| Chat (Google) | Ручні span-и | N/A (немає MCP tool loop) |
Обмеження¶
- Накладні витрати. Кожен span додає навантаження на CPU й пам’ять. На дуже високому трафіку має сенс тримати Phoenix вимкненим (
PHOENIX_ENABLED=false) і вмикати лише для дебагу. Ручні span-и додають мінімальний overhead, коли tracer =None. - Автоінструментація = чорна скринька. Версії LangChain/LangGraph і пакетів openinference краще тримати узгодженими.
- Ручні span-и мілкіші за автоінструментовані.
LangChainInstrumentorловить кількість токенів, текст prompt/completion, параметри моделі. Ручні span-и несуть лише атрибути, які ми явно задали, provider, model, tool name. Якщо потрібна деталізація на рівні токенів для OpenAI/Ollama chat, треба парсити відповідь і додавати в span. - Voice LLM працює на фронтенді. Gemini Live audio streaming йде через WebRTC у браузері, на бекенді немає LLM-виклику, який можна трейсити. Ми бачимо лише tool invocations, що повертаються на сервер.
- Це не заміна логів і алертів. Phoenix показує трейс виконання, а не бізнес-метрики чи SLO. LangSmith у проєкті лишається окремим світом, якщо ти його вже використовуєш. Phoenix не «вбиває» LangSmith автоматично, а лише додає ще один канал, якщо ти його увімкнув.
Що далі¶
Закріпити в документації SETUP крок «як увімкнути Phoenix». Розглянути додавання OpenInference інструментаторів для OpenAI (openinference-instrumentation-openai), якщо потрібні багатші LLM span-и для Izabella chat. Тоді з’являться кількість токенів і текст prompt без ручного парсингу. Phoenix тут лише інструмент для розбору конкретного прогону, а не єдине джерело правди про здоров’я системи.