AI-суверенітет: своя модель на DGX Spark замість API¶

Чому взагалі про це думати¶
Платити OpenAI, Anthropic чи Google за API зручно. До того моменту, поки ти не починаєш:
- ганяти персональні дані клієнтів через чужі сервери;
- дивитись на рахунок за місяць і рахувати, скільки це в токенах на добу;
- залежати від того, що провайдер завтра не деприкейтить твою модель або не підніме ціну;
- працювати в авіарежимі, у потягу або просто в офісі без інтернету.
У мене зійшлися всі чотири пункти одночасно. Тому поставив собі NVIDIA DGX Spark і запустив на ній vLLM як локальний OpenAI-сумісний сервер. Нижче розповідаю, що з цього вийшло, де я наступив на граблі, і чому це досі не «просто встановити і користуватись».
Одразу обмеження: якщо тобі потрібен GPT-5 рівень якості, локально ти його не отримаєш. Це розмова про відкриті моделі на 30-70B параметрів з пристойною якістю для своїх задач, не про заміну фронтир-моделей.
Що таке DGX Spark на практиці¶
DGX Spark, це компактна коробка на базі GB10 Grace-Blackwell. Ключове з того, що впливає на код:
| Параметр | Значення |
|---|---|
| GPU | NVIDIA GB10, compute capability sm_121 |
| Пам'ять | 121 GB LPDDR5X, юніфікована з CPU |
| CPU | ARM Cortex-X925 + A725, 20 ядер |
| Архітектура | aarch64 (не x86, не Tegra) |
| CUDA | 13.0 |
| OS | Ubuntu з NVIDIA-ядром |
Тут немає окремої VRAM. CPU і GPU ділять один пул LPDDR5X. Це означає, що nvidia-smi показує Memory-Usage: Not Supported, і якщо хтось хоче знати, скільки пам'яті реально вільно, доводиться робити так: |
import torch
free, total = torch.cuda.mem_get_info(0)
З юніфікованою пам'яттю є приємний бік: копіювання host до device майже безкоштовне. Але є й зворотній: будь-який жирний процес на CPU з'їдає ту саму пам'ять, яка потрібна моделі. І tensor_parallel_size > 1 тут не має сенсу, бо GPU рівно один.
Ollama, Ollama server, vLLM: що вибрати¶
Перед тим як полізти в vLLM, я півроку сидів на Ollama. Коротке порівняння того, що між ними реально відрізняється на практиці.
| Критерій | Ollama (desktop) | Ollama у server mode | vLLM |
|---|---|---|---|
| Поріг входу | brew install і пішов |
systemd unit або контейнер | pip, потрібен правильний .whl пакет під CUDA |
| Формат моделей | GGUF (llama.cpp) | GGUF (llama.cpp) | HF safetensors (full precision, AWQ, GPTQ) |
| API | OpenAI-сумісний (частково) + власний | те саме, через HTTP | OpenAI-сумісний, покриває більше ендпоінтів |
| Батчинг запитів | послідовний, по одному | послідовний | continuous batching, паралельні запити без втрати throughput |
| Швидкість на одному запиті | пристойна | пристойна | швидше на великих контекстах і довгих генераціях |
| Швидкість під навантаженням | падає лінійно | падає лінійно | тримає 5-10x більше одночасних запитів |
| KV cache | базовий | базовий | PagedAttention, ефективне використання пам'яті |
| Prefix caching | немає | немає | є, ріже TTFT на повторних префіксах |
| Квантизації | Q4/Q5/Q8 GGUF «з коробки» | те саме | AWQ, GPTQ, FP8; GGUF через додаткові збірки |
| Моніторинг | нуль | базовий health | /metrics Prometheus з TTFT, TPOT, throughput, cache hit |
| Керування пам'яттю | автозвільнення | автозвільнення | явний --gpu-memory-utilization, тримає модель постійно |
| Установка на DGX Spark (aarch64 + CUDA 13) | працює одразу після brew/офіційного інсталятора |
працює одразу | треба вручну підібрати .whl пакети під aarch64 + cu130, інакше падає на імпорті (деталі нижче) |
Ось чому я перейшов. На одному запиті різниця невелика. Але коли в тебе одночасно крутиться чат, автодоповнення в IDE, embedding pipeline і ще скрипт сходив спитати щось, Ollama починає вишиковувати їх у чергу. vLLM, завдяки continuous batching і PagedAttention, обслуговує їх одночасно і віддає метрики, за якими видно, де насправді вузьке місце.
Тепер про зворотний бік. vLLM:
- важче ставиться, особливо на нестандартному залізі (як моя коробка);
- не має зручного менеджменту моделей з коробки (немає
ollama pull qwenякий просто працює); - жере більше пам'яті «в простої», бо тримає кеш і preallocation;
- для поодинокого домашнього чату з однією моделлю, Ollama і досі кращий вибір.
Тобто я не кажу «vLLM завжди виграє». Він виграє, коли в тебе багатокористувацький сценарій або потрібні метрики продакшн-рівня. Для одиночного «поговорив з моделькою на вечір», Ollama зручніший.
До речі, перше що я зробив на свіжій Spark, це видалив Ollama:
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm -f /usr/local/bin/ollama /etc/systemd/system/ollama.service
rm -rf ~/.ollama
Вона висіла фоном і відкушувала GPU-пам'ять, яку я хотів віддати vLLM. Юніфікована пам'ять не прощає такого сусідства.
Перше правило vLLM: правильний .whl файл¶
Коротке пояснення для тих, хто не сидить у Python щодня. Коли ти робиш pip install torch, pip качає не вихідники, а заздалегідь скомпільований бінарний пакет з розширенням .whl (wheel). Для PyTorch таких збірок десятки: різні версії Python (cp310, cp312, cp313), різні архітектури процесора (x86_64, aarch64), різні версії CUDA (cu121, cu124, cu130). Якщо pip взяв не той файл, ти побачиш це тільки при імпорті, коли воно впаде.
Ось чому це важливо. Якщо ти просто зробиш pip install torch на DGX Spark, швидше за все отримаєш один з двох варіантів:
.whlпідx86_64, який на aarch64 падає зIllegal instruction;.whlпідcu121абоcu124, який на CUDA 13 падає зundefined symbol: cuTensorMapEncodeTiled.
Робочий варіант, це aarch64 + cu130. На PyPI далеко не всі пакети мають такі збірки. Я беру їх з офіційного індексу PyTorch:
pip install torch --index-url https://download.pytorch.org/whl/cu130
У requirements.txt мого проекту зафіксовано саме те, що протестовано на цій машині:
vllm==0.19.0+cu130
huggingface_hub[cli]==1.11.0
fastapi==0.135.3
uvicorn==0.44.0
sse-starlette==3.3.4
Python, до речі, 3.12. Спокуса оновитись до 3.13 є, але не всі +cu130 пакети мають cp313 збірку (це тег Python 3.13 у назві файлу). Перевіряй перед апгрейдом.
Друге правило: LD_LIBRARY_PATH обов'язковий¶
Але тут є проблема. Навіть з правильними .whl пакетами торч на цій коробці без підказки не знайде системні CUDA-бібліотеки. Перед будь-яким import torch або import vllm потрібно додати:
/usr/lib/aarch64-linux-gnu/libcusparseLt/13
/usr/lib/aarch64-linux-gnu/nvshmem/13
/usr/local/cuda-13.0/targets/sbsa-linux/lib
/usr/lib/aarch64-linux-gnu
Саме в такому порядку. Без цього ти отримаєш або libcusparseLt.so.0: cannot open shared object file, або тихий фейл на nvshmem. У мене це зашите в run_webapp.py і в коді, що запускає vLLM-процеси:
_cuda_libs = [
"/usr/lib/aarch64-linux-gnu/libcusparseLt/13",
"/usr/lib/aarch64-linux-gnu/nvshmem/13",
"/usr/local/cuda-13.0/targets/sbsa-linux/lib",
"/usr/lib/aarch64-linux-gnu",
]
os.environ["LD_LIBRARY_PATH"] = ":".join(_cuda_libs) + ":" + os.environ.get("LD_LIBRARY_PATH", "")
Коли я запускаю vLLM-сервер як дочірній процес з веб-інтерфейсу, я передаю цей LD_LIBRARY_PATH у дочірнє середовище явно. Інакше процес з великою ймовірністю не підніметься.
Ollama, до речі, цього не вимагала, бо вона статично лінкована з llama.cpp і не чіпає системну CUDA. vLLM, навпаки, йде через PyTorch і системні бібліотеки, тому кожну залежність треба знайти.
Третє правило: попередження про sm_121 можна пережити¶
На import torch ти побачиш:
UserWarning: Found GPU0 NVIDIA GB10 which is of cuda capability 12.1.
Minimum and Maximum cuda capability supported by this version of PyTorch is (8.0) - (12.0).
PyTorch 2.10 офіційно підтримує до sm_120. GB10, це sm_121. Насправді воно працює: ядра або лягають через PTX JIT, або відкочуються на sm_120. Для інференсу vLLM це стабільно.
Але якщо ти компілюєш власні CUDA-розширення (xformers з нуля, bitsandbytes, apex), PTX-fallback може не спрацювати. Тому:
- для інференсу відкритих моделей через vLLM, усе ок;
- для тренування з кастомними оптимізаторами доведеться або чекати офіційний sm_121, або збирати руками з
TORCH_CUDA_ARCH_LIST="12.1".
vLLM як OpenAI-сумісний сервер¶
Тепер коли залежності стоять, запуск моделі, це одна команда:
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-Coder-32B-Instruct \
--dtype auto \
--port 8000 \
--max-model-len 8192 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9
Після цього на http://localhost:8000/v1/chat/completions підіймається той самий API, що й у OpenAI. Мій VS Code з Continue, Cursor з custom endpoint, Open WebUI, будь-який клієнт з підтримкою OpenAI протоколу, працюють без змін. Просто підставляєш свій base URL і фіктивний ключ.
Це і є суть. Ти не переписуєш клієнтів, ти підміняєш бекенд.
Але є обмеження, які треба назвати:
- Одна велика модель за раз. Якщо це 30-35B у bf16, то так, більше не влізе. Але кілька маленьких сервісів (наприклад, кодова + реренкер + embedder) можна підняти паралельно з акуратним бюджетом по пам'яті. Розділ про 3 моделі одночасно нижче.
- Холодний старт 5-10 хвилин. Перший запуск моделі компілює кеш Triton і FlashInfer. Наступні старти вже швидкі, кеш у
~/.tritonі~/.cache/flashinfer. - 30B моделей, це практична стеля для однієї моделі на цій коробці в bf16. 70B у квантизації теж заходять, але з меншим контекстом.
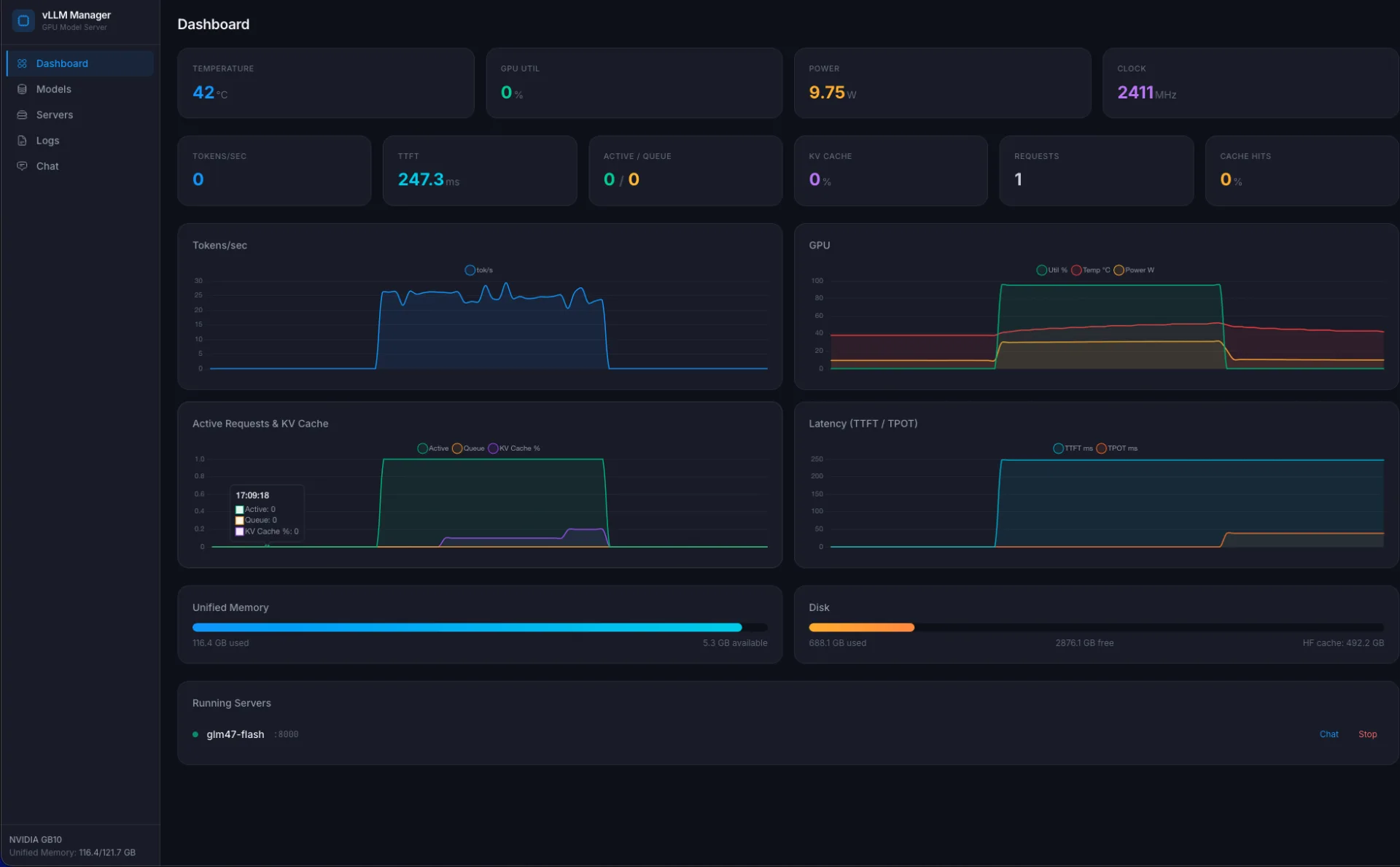
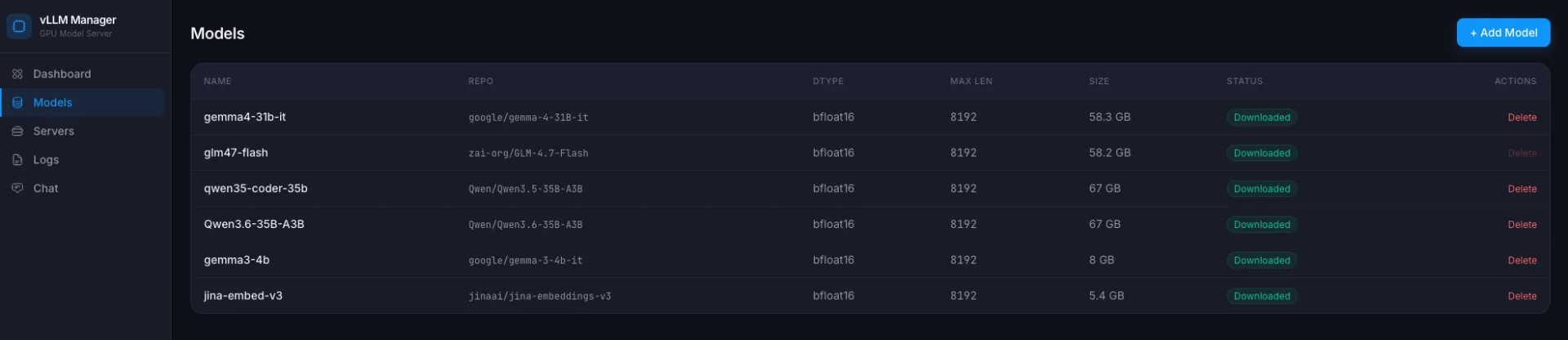
Веб-інтерфейс для керування¶
CLI-скрипти це добре, поки ти один. Коли я хочу переключати моделі з ноутбука або просто бачити, що зараз крутиться і скільки воно жере, CLI незручно. В Ollama для цього є Open WebUI і сама ollama list. У vLLM, нічого подібного з коробки немає. Тому я написав тонкий веб-шар на FastAPI.
Що він уміє:
- список профілів моделей з Hugging Face (додати / видалити / скачати);
- запустити / зупинити vLLM-сервер для обраної моделі;
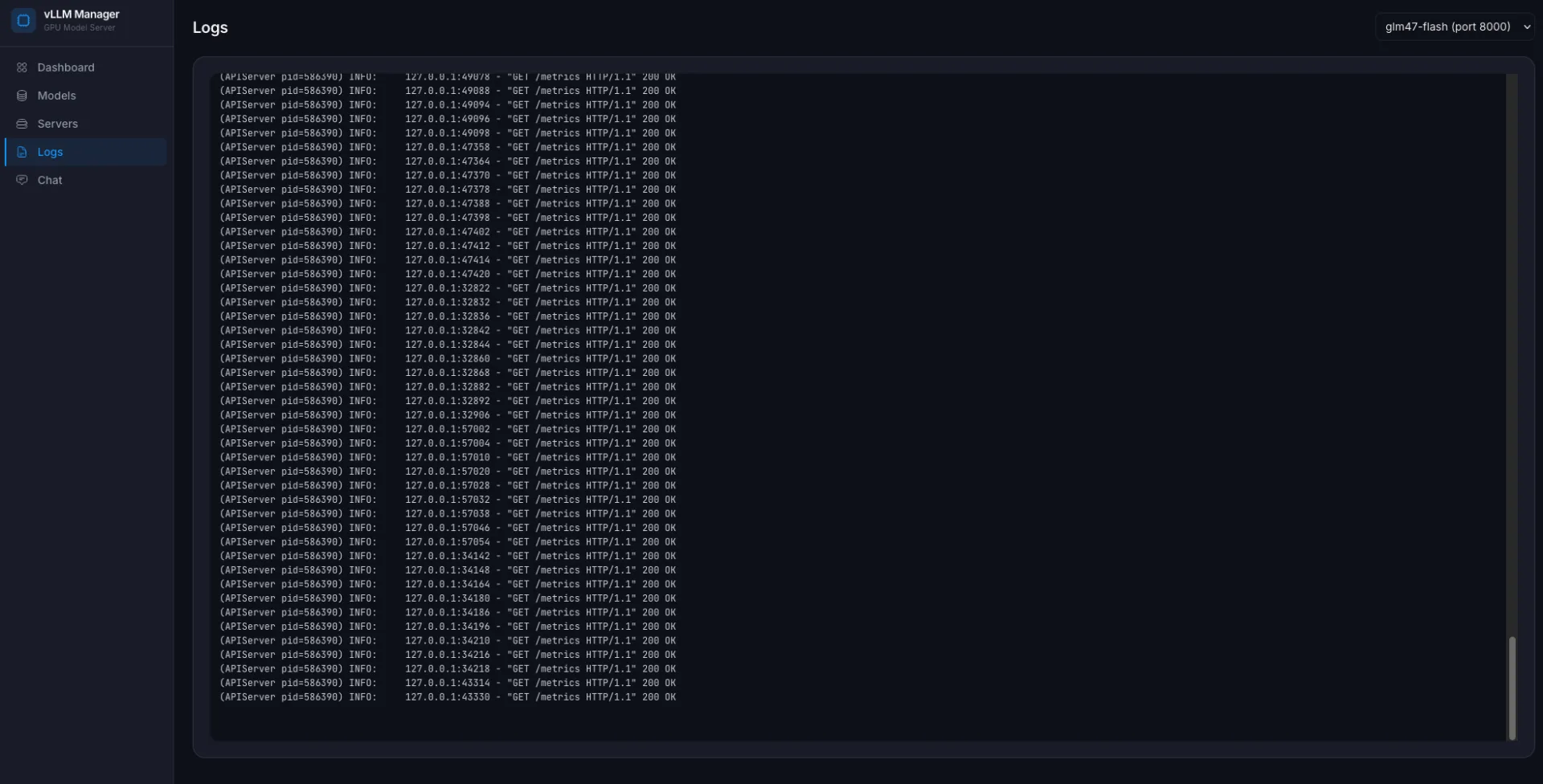
- стрімити логи завантаження і старту моделі в браузер через SSE;
- показувати метрики GPU (температура, споживання, utilization), пам'яті і диска;
- читати
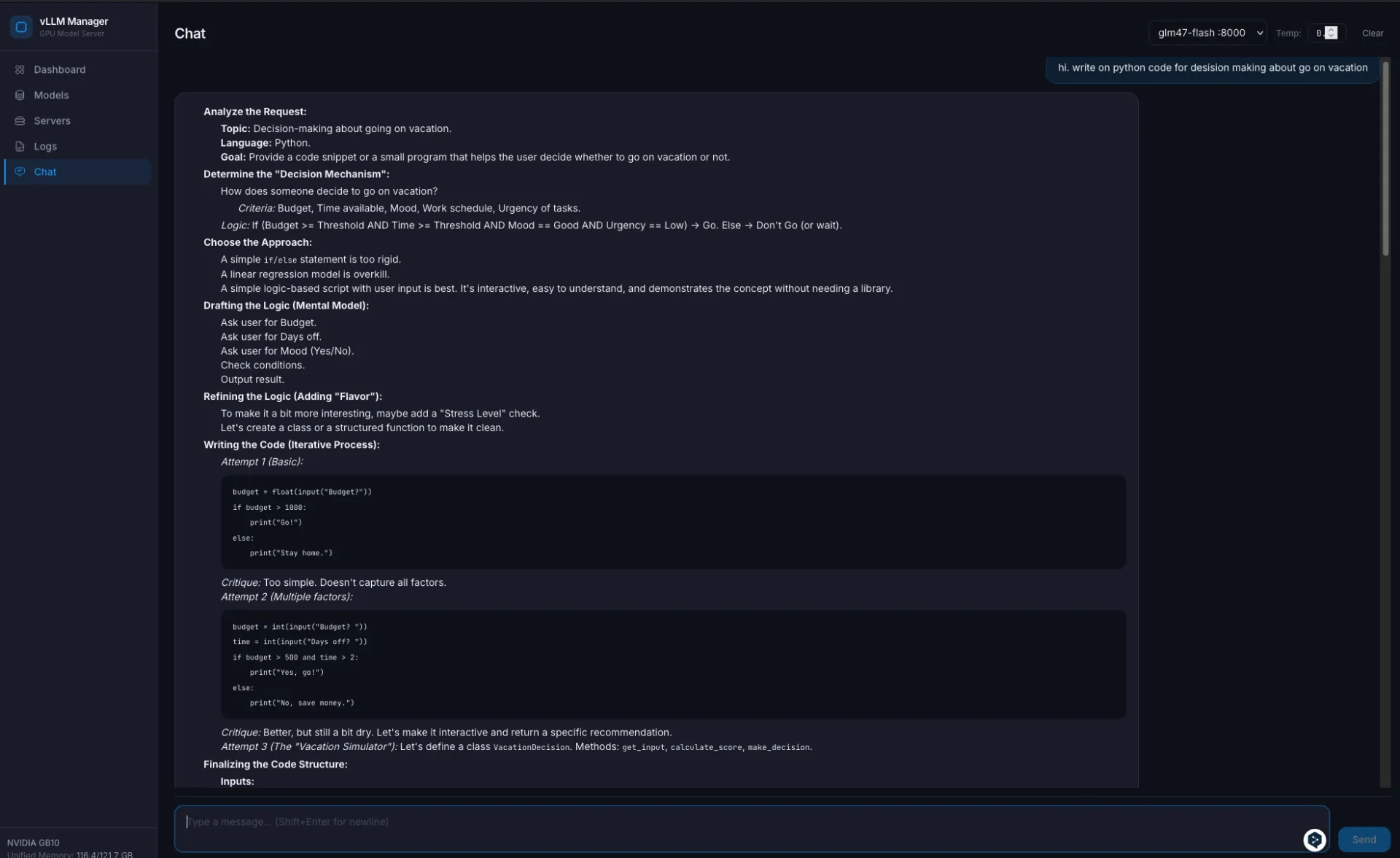
/metricsз vLLM і показувати tokens/sec, TTFT, TPOT, cache hit rate; - чат-вікно, яке проксить в локальний vLLM через OpenAI API.
Стек простий: FastAPI + sse-starlette для стрімів, psutil для метрик, httpx для походу в vLLM /metrics і /v1/chat/completions. Фронт, це Alpine.js + Chart.js без бандлерів, один HTML на 30 KB.
Як це виглядає¶
Структура¶
webapp/
main.py роутери і статика
core.py вся логіка (конфіги, subprocess, GPU, метрики)
models.py Pydantic DTO
routers/
profiles.py CRUD профілів
downloads.py hf download + SSE прогрес
servers.py start/stop + /health + startup stream
logs.py tail -f через SSE
gpu.py GPU/memory/disk + інференс-метрики
chat.py проксі в OpenAI API
static/
index.html one-pager на Alpine
Вся робота з файлами і процесами лежить в одному core.py. Роутери, це тонкі обгортки. Хочу щось нове, правлю одну функцію в одному місці.
Як стрімиться прогрес завантаження моделі¶
Hugging Face CLI пише прогрес у stderr рядками. Я стартую дочірній процес, читаю обидва потоки в asyncio.Queue, а клієнт підписується на цю чергу через Server-Sent Events:
async def download_model(name: str, queue: asyncio.Queue):
cmd = [str(VENV_HFCLI), "download", model["repo"]]
proc = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
# читаємо і stdout, і stderr; кожен рядок у queue
...
await queue.put(None) # сентинел для закриття стріму
На фронті звичайний EventSource. Ніяких WebSocket-ів, ніякого polling.
Як я не пускаю запустити дві моделі одночасно¶
Пам'ять одна. Тому при старті нового сервера я спершу дивлюсь на список активних:
def start_server(model_name, port, gpu_memory_utilization=None):
running = list_servers()
if running:
names = ", ".join(s.model_name for s in running)
raise RuntimeError(
f"Server already running: {names}. Stop it before starting a new one."
)
model_size = get_model_size_gb(model["repo"])
if model_size:
free_gb = get_gpu_free_memory_gb()
if free_gb is not None and model_size > free_gb:
raise RuntimeError(
f"Not enough GPU memory: model needs ~{model_size} GB "
f"but only {free_gb:.0f} GB free"
)
list_servers дивиться і в свій servers.json, і в ps на предмет чужих vllm.entrypoints.openai.api_server. Якщо хтось запустив vLLM повз мій веб-шар, я його бачу як external-<pid> і можу зупинити.
Вбити vLLM, це не один SIGTERM¶
Ось що я дізнався важкого шляху. У vLLM 0.19 движок ганяє процеси VLLM::EngineCore як дочірні. Плашка SIGTERM батька іноді залишає їх осиротілими і пам'ять на GPU висить. Тому stop, це:
- SIGTERM на tracked PID;
- чекаю 30 секунд;
- SIGKILL, якщо не вмер;
- проходжусь по
/proc, шукаю будь-якіVLLM::EngineCoreвід мого користувача і вбиваю їх окремо.
Без останнього кроку ти вбиваєш парента, перезапускаєш нову модель, отримуєш CUDA out of memory на моделі, яка точно мала влізти. Класика. В Ollama такого не було, там процес один і він чистий.
Метрики: як я дізнаюсь, що все працює¶
vLLM віддає prometheus-сумісний ендпоінт /metrics. Мені не потрібен повноцінний Prometheus для одного хоста, тому я просто парсю текст сам:
def _parse_metric(name: str, text: str) -> float:
val = 0.0
for line in text.split("\n"):
if line.startswith(name + "{") or line.startswith(name + " "):
parts = line.rsplit(" ", 1)
if len(parts) == 2:
try:
val = float(parts[1])
except ValueError:
pass
return val
З цього я витягую: vllm:generation_tokens_total, vllm:num_requests_running, vllm:kv_cache_usage_perc, суми і counts з гістограм для TTFT і TPOT. Tokens/sec рахую як дельту по таймеру. На фронті, це Chart.js з останніми 120 точками.
Для GPU беру те, що віддає nvidia-smi --query-gpu=...,noheader,nounits. Це дає температуру, utilization, power draw, performance state. Пам'ять GPU, як я згадував, беру через torch.cuda.mem_get_info, запускаючи окремий короткий Python-процес (бо сам веб-шар свідомо не імпортує торч).
Ось тут і є різниця з Ollama. У неї подібних метрик просто немає. Якщо тобі важливо знати, що саме гальмує генерацію (префіл чи декодинг), і скільки реально вільно в KV-кеші, vLLM дає відповідь зразу.
Бенчмарки: як я порівнюю моделі¶
Перші спроби були ad-hoc: запустив, запитав, подивився секундомір. Цифри скакали на 20-30%, довіри нуль. Тому переклав усе на vllm bench serve. Це стандартний інструмент від vLLM-команди, він сам робить warmup, ловить steady-state, рахує перцентилі латентності і віддає JSON, який легко агрегувати.
Робочий сценарій фіксований, щоб числа можна було порівнювати між моделями:
--dataset-name random, 512 input / 256 output токенів;--num-prompts 100,--request-rate inf, щоб бенч тиснув на систему, а не навпаки;- ShareGPT я свідомо не беру: різні токенайзери з того самого тексту роблять різну кількість токенів, і throughput уже не порівнюваний.
Методологія докручувалась у три ітерації:
| Версія | Зміна | Навіщо |
|---|---|---|
| v1 | Базовий прогін | Дав результат, але між Qwen3.5 і Qwen3.6 була підозріло велика різниця |
| v2 | NUM_WARMUPS=5, вирівняв профіль Qwen3.6 (dtype=bfloat16, max_model_len=32768) |
Зняв JIT-холодний старт і перекіс по dtype |
| v3 | NUM_REPEATS=3 + медіана |
Замість одного сумнівного числа, тепер триразовий прогін і медіана |
Скрипт і регулярні прогони¶
Все керується одним шел-скриптом /home/igogo/vllm-tools/bench_models.sh. Він:
- читає список моделей з
~/.config/vllm-models/models.json; - на кожну модель піднімає vLLM через мій
vllm_models.py serve, чекає на health; - усередині однієї сесії прогоняє
vllm bench serveN разів (steady-state, без перезавантажень); - рахує медіану через
jq, дописує один рядок у~/.config/vllm-models/benchmarks/summary.csv; - зупиняє сервер і переходить до наступної моделі;
- зберігає per-run JSON для аудиту (
BENCH_KEEP=20); - має прапорець
--if-idle, щоб виходити з кодом 0, якщо на коробці вже щось крутиться.
На systemd user-тімер це лягло так:
~/.config/systemd/user/vllm-bench.service, oneshot, викликаєbench_models.sh --if-idle, timeout 3 години;~/.config/systemd/user/vllm-bench.timer,OnCalendar=Sun 04:00,RandomizedDelaySec=30m,Persistent=true.
Щонеділі вночі воно пробігає по всіх моделях, якщо GPU вільний. Якщо я в цей момент щось запустив, воно чисто виходить і не вбиває мою роботу. Перевіряти статус, це journalctl --user -u vllm-bench.service і systemctl --user list-timers vllm-bench.timer.
Результати v3 (медіана з трьох прогонів, 2026-04-18)¶
| Модель (локальний профіль) | output tok/s | total tok/s | TTFT медіана | TTFT p99 | TPOT медіана |
|---|---|---|---|---|---|
| glm47-flash | 337.2 | 1011.5 | 1.98 s | 2.30 s | 289 ms |
| qwen35-coder-35b | 273.4 | 820.3 | 8.04 s | 17.22 s | 325 ms |
| qwen36-35b-a3b | 270.9 | 812.7 | 8.18 s | 16.96 s | 331 ms |
| gemma4-31b-it | 81.5 | 244.5 | 22.38 s | 33.26 s | 910 ms |
Що з цього видно:
- GLM flash-варіант лідирує з помітним відривом. Ранні прогони давали йому TTFT ~7 секунд, але після warmup стало 2, тобто перший приклад був артефактом старту.
- Дві Qwen-моделі тотожні в межах 1%. Розрив у v1 був не через архітектуру, а через
dtype=auto+max_model_len=8192+ відсутність warmup на одній з них. Якщо тобі хтось показує перевагу моделі X над Y без warmup і без фіксованого профілю, це, скоріш за все, шум. - Gemma 4 на 31B щільна, а Qwen-и це MoE з активними 3B на токен. Різниця в 3x, це не конфіг, це архітектура. Очікувано.
Варіація між повторами, приблизно 1%. Бенч відтворюваний, цифрам можна вірити в межах цього шуму.
Якість (наскільки відповіді корисні на моїх задачах) я свідомо не включаю в автоматичний бенч. Throughput і TTFT це те, що можна міряти без людини. Якість потребує окремого eval-сету, над цим ще працюю.
Що я отримав на виході¶
- Набір профілів для моделей вище, переключаю через веб-інтерфейс під задачу.
- Qwen Coder 32B в Cursor як
Custom OpenAI endpoint, Gemma 3 27B для чату, Llama 3.3 70B AWQ для складніших reasoning-задач. - Рахунок за OpenAI впав приблизно на 80%. Лишається в основному GPT-5 для фронтир-задач.
- Дані клієнтів не виходять за межі моєї машини.
- Паралельні запити з Cursor, Continue і власних скриптів не чергуються, vLLM їх батчить.
Економіка: скільки це коштує насправді¶
Щоб не було враження «суверенітет, це безкоштовно», нижче чесна арифметика. Цифри станом на квітень 2026, тож перевіряй актуальні перед покупкою.
Апфронт, залізо¶
- DGX Spark Founders Edition (128 GB, 4 TB NVMe), приблизно $3,999 за MSRP. У наявності буває важко, у перекупів бачив +15-20% зверху.
- UPS на 500-700 Вт (щоб не втратити компіляцію Triton при збоях), ~$150-300.
- 10 GbE мережа, якщо хочеш не по Wi-Fi: маленький світч і кабелі, ~$200-300.
- Додатковий NVMe під HF cache, моделі важать по 20-60 GB кожна, легко набігає 500 GB+. ~$120 за 2 TB.
- Охолодження приміщення, якщо коробка в невеликій кімнаті, воно гріє. У мене обійшлось без апгрейду.
Разом, стартове вкладення виходить ~$4,500.
Місячно, електрика¶
- Під навантаженням Spark тягне приблизно 240 Вт. В idle, ~60 Вт.
- Реалістичний duty cycle у мене, 30-40% (робота, кава, мітинги, сон).
- Місячне споживання, орієнтовно 60-80 кВт·год.
- Моя ставка в Києві (квітень 2026), ~4.3 UAH за кВт·год, або приблизно $0.10.
- Виходить $7-10 на місяць за струм.
- Для порівняння: у Німеччині при ставці ~$0.30, це були б $20-25/місяць.
Для порівняння, API, який я перестав платити¶
Орієнтовні прайси станом на квітень 2026, перевіряй офіційні таблиці:
| Провайдер / тариф | Ціна | Коли беру |
|---|---|---|
| OpenAI GPT-4o Mini | $0.15 / $0.60 за 1M токенів | Дешеві масові задачі |
| OpenAI GPT-5 (або аналог) | ~$3 / ~$15 за 1M токенів | Більша частина «серйозного» коду |
| Claude Sonnet 4.6 | $3 / $15 за 1M | Альтернатива для коду і документації |
| Claude Opus 4.7 | $15 / $75 за 1M | Фронтир, рідко |
| Cursor Pro | $20/місяць | Ліміти розлітаються, якщо кодиш щодня |
| Cursor Business | $40/місяць/людину | Командний тариф |
Мій break-even у цифрах¶
До переїзду я платив щомісяця:
- Cursor Business, $40;
- OpenAI API напряму для скриптів і агентів, $80-150;
- Claude API для документації і RAG, $50-100.
Разом виходило $170-290/місяць, середнє близько $220.
Після Spark:
- Cursor Pro (не Business), $20, для фронтир-задач через тунель;
- API-трафік залишився для того, що локально крутити не хочеться, $30-50;
- Електрика, ~$10.
Разом $60-80/місяць. Економія виходить приблизно $150/місяць.
При апфронті $4,500 break-even виходить ~30 місяців, тобто 2.5 роки. Якщо виключно по грошах, це довго. Для мене ключовий фактор, це не економія, а суверенітет даних і офлайн. Економія, це приємний бонус, а не головний driver.
Підсумок: якщо ти не платив більше ніж $150-200/місяць за API до того, Spark тобі фінансово не окупиться. Він для тих, хто вже ганяв багато платних токенів і кому муляло приватність.
Кластер 3-5 Spark-ів, цифри¶
- 3 коробки, ~$12,000 тільки за залізо. Плюс QSFP-світч на 100-200 GbE, ~$2,000-5,000. Плюс кабелі, стійка, PDU, ще ~$1,000.
- 5 коробок, ~$20,000 + ~$5,000 на мережу.
- Електрика під навантаженням 5 нод, до 1.5 кВт з розетки. У Києві це ~$40/місяць, у Німеччині до $150.
Економіка кластера починає сходитись, якщо:
- команда 20+ людей ділить одну модель, сумарний API-чек би був $2-5K/місяць;
- або в тебе критичне обмеження на передачу даних назовні, і ціна приватності важить більше за гроші.
Для однієї людини кластер, це переплата. Одна коробка закриває індивідуальні задачі з запасом.
Де воно не заходить¶
- Якщо тобі треба GPT-5 рівень, DGX Spark не допоможе. Фронтир-якість все одно потрібна через API.
- Холодний старт моделі 5-10 хвилин, не годиться для рідкісних разових запитів. Треба тримати процес піднятим.
- Один GPU = одна модель. Якщо ти чергуєш кілька, готуйся до downtime на переключення.
- Залізо коштує грошей. Break-even проти API настає приблизно через 6-12 місяців інтенсивного використання, залежно від профілю.
- Квантизовані 70B моделі вимагають більше терпіння і дають менший контекст. Це реальний компроміс, а не маркетинг.
- Якщо тобі потрібен просто «запустив і поговорив» для однієї людини, Ollama робить це простіше. vLLM окуповується, коли ти ділиш модель між кількома клієнтами або ганяєш через неї batch-пайплайни.
Три моделі одночасно на одній коробці¶
Раніше я писав «одна модель за раз». Це правда для випадку «коли модель на 30-35B у bf16». Але в реальному робочому процесі часто треба не одну жирну модель, а три сервіси різного розміру:
- коддерка для IDE (Qwen Coder 35B в MoE/A3B);
- реренкер для RAG (Gemma 3 4B). Про що це коротко: після швидкого векторного пошуку ти отримуєш список з 10-50 кандидатів. Реренкер, це модель, яка бере пару «запит + кожен кандидат» і переставляє їх у правильному порядку релевантності. Вона точніша за cosine similarity ембедингів, але повільніша, тому викликається тільки на фінальному етапі;
- embedder для векторного пошуку (Jina v3 або BGE-M3).
Якщо акуратно розрахувати бюджет по пам'яті, воно заходить:
| Сервіс | Порт | Движок | gpu_memory_utilization |
Приблизний footprint |
|---|---|---|---|---|
| coder (Qwen 35B A3B) | 8000 | vLLM | 0.70 | ~85 GB |
| reranker (Gemma 3 4B) | 8001 | vLLM | 0.15 | ~18 GB |
| embedder (Jina v3) | 8002 | TEI (Docker) | — | ~5 GB |
| Разом | ~108 GB / 121 GB | |||
| ОС, веб-шар, буфери | ~13 GB |
Впритул, але працює. Ключовий момент тут, це --gpu-memory-utilization на кожному vLLM явно вказаний і в сумі не перевищує ~0.85. І embedder я свідомо не ганяю через vLLM.
Чому embedder окремо через TEI¶
vLLM генеративний за природою, і для embedding-моделей він не оптимізований. Для цього є Hugging Face Text Embeddings Inference (TEI), покладений у Docker. На batch-навантаженні TEI вдвічі-втричі ефективніший, бо робить те, для чого заточений: матрицю ембедингів без авторегресії, без KV-кешу, без sampler-а.
Трейд-оффи, які треба знати¶
- Вузьке місце тепер, це обчислення, а не пам'ять. Один Blackwell-чип, SM один на всіх. Коли coder у гарячому батчі, а класифікатор молотить, SM-конкуренція б'є по TPOT у кодерки. Під час bulk-класифікації код пише повільніше.
- Шина пам'яті LPDDR5X теж одна. Embedder дешевий, реренкер конкурує з кодеркою за bandwidth.
- Практична порада: масові імпорти для класифікації ганяй вночі як batch. Embedder і реренкер можна тримати постійно (idle-коштують майже нуль), coder піднімай тільки коли реально кодуєш. Так один одному не заважають.
Обмеження CLI, яке я ще не закрив¶
vllm_models.py досі тримає один PID-файл і дозволяє запустити рівно один сервер. Піднімати дві моделі треба або через веб-шар (там у servers.json уже багатосерверна модель і start_server у webapp/core.py це підтримує), або напряму руками через python -m vllm.entrypoints.openai.api_server ....
Привести CLI до паритету з веб-шаром, це окремий маленький тудушник. Якщо тобі CLI-first, краще його зробити, інакше запускати кілька моделей вручну незручно.
Класифікатор файлів: реальний use case для всього цього¶
Тепер навіщо взагалі тримати три сервіси. У мене є особистий архів документів, який накопичувався роками. Треба його розкласти по ієрархічній таксономії з jd.yaml (це частина agentic-ai-landing-zone): ~400 листових класів, три рівні глибини, категорії від «10 Finance» до «55 Woodcarving», зміст EN / UK / RU, файли від коротких заголовків до багатокілобайтних PDF.
Чому fine-tune класичного енкодера тут поганий варіант¶
- 400 класів × ~50 прикладів на клас, це 20K ручних анотацій. Я не хочу.
- Клас-оверлапи: Elasticsearch живе і під Databases/Search, і під DevOps. ClickHouse так само. Класифікатор з фіксованими мітками зламається на цих конфліктах.
- Додати новий клас = перетренити модель. Таксономія жива, це не ок.
Архітектура: retrieval + rerank¶
Два етапи.
Етап 1, семантичний retrieval. Один раз плющу jd.yaml у рядки з ієрархічним контекстом (наприклад, "10.06.03 Finance / Expenses / Food — grocery receipts, restaurant bills"). Усі ~400 міток ембеджу і складаю у FAISS (in-process). Для кожного файлу беру filename + перші 4KB контенту, ембеджу, дістаю top-5 кандидатів за cosine similarity.
Етап 2, LLM-реренкер (тільки коли треба). Реренкер у класичному RAG, це спеціальна невелика модель (на зразок bge-reranker-v2-m3), яка отримує пару «текст + кандидат» і видає score релевантності. Тут замість такої моделі я використовую маленький LLM, щоб він не просто переставив кандидатів, а ще й пояснив вибір і дав confidence. Логіка проста: якщо top1_score - top2_score > 0.15, беру top-1 напряму і нікого не турбую. Інакше маленький LLM отримує уривок файлу + 5 кандидатів + опис кожного і вибирає один. Реренк спрацьовує орієнтовно на 20-30% файлів.
Вибір моделей¶
Embedder, критична ланка, бо має тримати EN + UK + RU і досить довгий контекст:
jina-embeddings-v3(570M, 8K контекст, 100+ мов) за замовчуванням. Task-specific prompting і multilingual непогані.- BGE-M3 як альтернатива (теж 8K, dense+sparse+multivec).
- mE5-large швидший, але 512 токенів контексту, для довгих документів доводиться чанкати.
Реренкер:
google/gemma-3-4b-itяк основний вибір за якістю UK/RU у 1-5B класі.- Qwen3-4B швидший, але слабший на UK/RU.
- Qwen3-1.7B, якщо реренк викликається рідко і важлива швидкість.
Що треба почистити в jd.yaml до деплою¶
Якщо таксономія дірява, будь-який класифікатор працюватиме погано. Перевірка, яку я собі поставив:
- розв'язати дублі (Elasticsearch у двох гілках, ClickHouse у двох гілках, IAM у двох гілках);
- видалити або злити порожні піддерева (
47 Observabilityvs46.13 Monitoring); - почати з level-2 (
10.06 Expenses, а не10.06.03 Food) і заглиблюватись поступово. Long-tail листки рідко матчаться з високою впевненістю, тому на старті вони тільки шумлять.
Очікувана пропускна здатність на GB10¶
- Embedder у TEI з batch-ом, ~1000-2000 текстів/сек.
- kNN по 400 векторах, миттєвий.
- LLM-реренк, коли спрацьовує, ~40 файлів/сек.
- Зважено (~70% файлів класифікується тільки ембедингом), виходить ~300-800 файлів/сек.
Тобто вечір ганяння архіву на кілька сотень тисяч документів, це цілком реально. І це саме той кейс, заради якого хочеться тримати три моделі підняті одночасно, а не перемикатися.
Маленькі моделі для класифікації: довідник¶
Коли треба щось швидке для розмітки тексту, ось що я тримаю в голові (специфіка під конкретну таксономію вище, це інша розмова).
Енкодери (найшвидші і точні, якщо є розмічені дані)
| Модель | Параметри | Коли брати |
|---|---|---|
| ModernBERT-large | 395M | Англійська, 8K контекст, поточний SOTA серед енкодерів |
| DeBERTa-v3-large | 435M | Англійська, класика на GLUE/MNLI |
| mDeBERTa-v3-base | 278M | Мультимовна з UK, найкращий баланс швидкість/якість |
| XLM-RoBERTa-large | 560M | Мультимовна, трохи точніша за mDeBERTa |
| DistilBERT / TinyBERT | 66M / 14M | CPU/edge |
Маленькі генеративні LLM (zero/few-shot класифікація)
| Модель | Параметри | Нотатки |
|---|---|---|
| Gemma-3-1B-it / 4B-it | 1B / 4B | Сильна UK/RU, мій дефолт для мультимовних small-LLM задач |
| Qwen3-1.7B / 3-4B | 1.7B / 4B | Трохи швидша за Gemma-3, слабша на UK/RU |
| Phi-4-mini | 3.8B | Сильний reasoning, слабша мультимовність |
| SmolLM2-1.7B | 1.7B | Найшвидша в класі, переважно англомовна |
| Llama-3.2-3B | 3B | Стабільна, але на класифікації слабша за Qwen3 |
А якщо зібрати 3-5 Spark-ів у кластер¶
Питання, яке мені ставлять частіше за все. Коротка відповідь: так можна, але з нюансами, і одиночна коробка перетворюється на мініатюрний HPC-кластер, а не на «x5 до швидкості».
Що дає більше коробок¶
Якщо поставити поруч 3-5 Spark-ів, ти отримуєш приблизно:
- 360-600 GB сумарної пам'яті (121 GB × N).
- 3-5 GPU sm_121, об'єднаних мережею.
- Можливість крутити моделі, які в одну коробку не влазять: Llama 3.1 70B в bf16 вільно, 405B у квантизації за умови правильного sharding.
- Відмовостійкість: одна нода впала, інші продовжують обслуговувати запити.
- Пропускну здатність для багатьох одночасних користувачів, а не швидкість одного запиту.
Як їх фізично з'єднати¶
NVIDIA офіційно підтримує з'єднання двох Spark-ів через ConnectX-7 (200 Gbps, QSFP). Це той самий офіційний «duo»-сценарій, під який є гайди.
Від трьох нод і далі, ти виходиш за межі офіційного сценарію і робиш звичайний HPC-кластер:
- QSFP-світч 200 GbE або InfiniBand поміж усіма нодами;
- або 100 GbE, якщо мережа не критична і ти готовий до просадки;
- спільне сховище для ваг моделей (NFS, Lustre або локальні кеші з синхронізацією).
Вартість мережі тут не нуль. Світч на 200 GbE з QSFP-портами плюс кабелі додають помітну частину до ціни самих Spark-ів.
Як це виглядає для vLLM¶
vLLM має два способи розподілити модель між кількома GPU:
--tensor-parallel-size, шарди кожного шару між GPU. Працює відмінно на одній коробці з NVLink, страждає від мережевої латентності, коли GPU в різних нодах. На Ethernet навіть 200 GbE це не NVLink.--pipeline-parallel-size, різні шари моделі на різних нодах. Менш чутливий до латентності, але не прискорює одиночний запит, а тільки додає пропускну здатність.
Реалістичний рецепт для 3-5 Spark-ів:
# на head-ноді
ray start --head --port=6379
# на кожній worker-ноді
ray start --address=head-ip:6379
# запуск vLLM через Ray
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-70B-Instruct \
--tensor-parallel-size 1 \
--pipeline-parallel-size 5 \
--distributed-executor-backend ray \
--port 8000
Тобто кожна Spark тримає частину шарів, запит проходить по конвеєру.
Чесні обмеження кластера¶
- Латентність одного запиту не падає, а часто зростає, бо пакети ганяються по мережі. Хочеш відповідь за 300 мс, один Spark і компактна модель, це краще.
- NCCL на aarch64 + cu130 працює, але це не така вторована стежка, як на x86. Я особисто очікував би кілька вечорів на дебаг мережевих фейлів.
- Холодний старт множиться. Кожна нода компілює свій кеш Triton/FlashInfer. Перший запуск 70B-моделі на п'яти нодах, це просто «пішов гуляти».
- Моніторинг ускладнюється. Замість одного
/metricsу тебе їх N, плюс метрики Ray, плюс мережа. Простого веб-шару, як у мене на одну коробку, вже буде мало. Треба нормальний Prometheus і дашборд. - Енергоспоживання. Кожна Spark це приблизно 240 Вт під навантаженням. П'ять штук, це більше 1 кВт з розетки плюс охолодження.
- Економіка не завжди сходиться. Кластер з 5 Spark-ів у ціні наближається до однієї H100-машини, але з гіршою latency на синхронних операціях. Вигідно, якщо тобі принципові суверенітет і відсутність залежності від одного вузла.
Коли воно реально має сенс¶
- Команда з 20-50 людей ганяє одну локальну модель: кластер Spark-ів дає throughput і HA.
- Треба крутити 70B+ моделі, а один Spark не тягне в потрібному контексті.
- Критичний офлайн-сценарій: один вузол впав, інші продовжили.
- RAG-пайплайн, де embedding + reranking + LLM живуть на різних нодах.
Коли не має¶
- Один користувач з одним IDE, одна Spark перекриває задачу з запасом.
- Потрібна низька latency на одному запиті (коли важливий перший токен).
- Немає бюджету на нормальну мережу, без 200 GbE це буде розчарування.
Особисто я поки зупинився на одній коробці і не шкодую. Але план на наступний рік, це саме пара Spark-ів з ConnectX-7, щоб тримати кодову модель окремо від загальної чатової. Далі за цим, тільки якщо задачі виростуть до командного рівня.
Що далі¶
У планах:
- автопереключення моделей під задачу (код, чат, embedding) з розумним прогрівом;
- акуратніший trace через OpenTelemetry, щоб бачити причину затримок на рівні конкретного запиту;
- RAG поверх локальної бази документів, щоб не ганяти контекст через API.
Для мене це вже не експеримент, а робочий інструмент. Але підіймалось воно не «за 5 хвилин з гайду». Ось чому я зібрав усі граблі в одному репозиторії і документую кожен нюанс окремо, щоб наступного разу не наступати двічі.
Якщо цікаво подивитись код веб-шару, скрипти керування моделями і повний файл з нюансами заліза, вони лежать у проекті vllm-manager. CLAUDE.md і HARDWARE.md там, це не формальність, а реальні робочі нотатки для майбутнього мене.